### 内容主体大纲1. **引言** - 加密货币的崛起 - 以太坊的价值与影响2. **Tokenim项目概述** - Tokenim的背景 - 项目的主要目...
卷积神经网络(CNN)是一种深度学习模型,主要用于图像处理任务,同时也被应用于自然语言处理(NLP)中的文本分类、情感分析等问题。传统的神经网络通过全连接层处理输入数据,而CNN则通过卷积层提取特征,具有更强的空间特征提取能力。
CNN的基本构成包含卷积层、池化层和全连接层。卷积层通过滤波器(卷积核)扫描输入数据,提取局部特征,池化层则通过下采样(如最大池化或平均池化)减少数据的维度与计算量,全连接层用于将提取的特征进行分类。
CNN工作原理的核心在于其使用的卷积操作,能够有效捕捉邻近元素之间的关系,这使得其在处理有空间结构的数据(如图像、文本)时,能够表现出色。
#### Tokenization(标记化)是什么,为什么重要?
Tokenization是将一段文本分割成若干个"token"的过程,这些token可以是单词、词组或子词。在自然语言处理(NLP)中,tokenization是将文本数据转化为机器能够理解的数字格式的第一步。
标记化的重要性在于它为后续的文本处理提供基础。准确的tokenization能够提高文本数据分析的效果,不同的tokenization方法会影响模型训练的表现和最终的结果。常见的方法包括空格分割、使用词汇表、Byte Pair Encoding(BPE)等。
#### 如何将Tokenization与CNNs结合?在使用CNN进行文本处理时,首先需要对原始文本进行tokenization,将其转变为数字序列。这些序列会被用作CNN的输入,经过卷积层和池化层后,提取出文本的特征。
在实际应用中,tokenization的选择会直接影响CNN性能的表现。例如,使用BPE进行tokenization时,可以有效处理未登录词(out-of-vocabulary)问题,从而使CNN能够处理多样化的文本数据。
#### Tokenization中的常见挑战有哪些?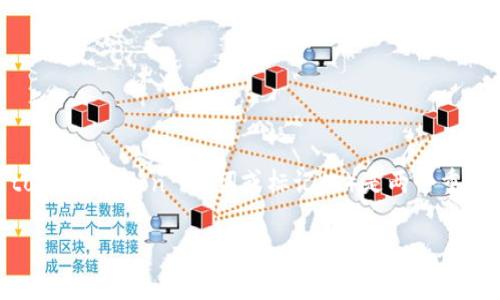
虽然tokenization是文本处理中的基本步骤,但在实施过程中存在一些挑战。例如,语言的复杂性导致单词可能有多种词形变化,此外多义词和同义词的处理也可能影响token的准确性。
为了应对这些挑战,研究人员和工程师经常需要结合上下文信息,对tokenization方法进行改进,以提高自然语言理解的准确性和效果。
#### CNN在文本数据处理中的限制是什么?尽管CNN在图像处理和文本分类任务中都取得了显著的成果,但在处理文本数据时也存在一些限制。例如,CNN通常只能考虑固定大小的上下文窗口,对于长文本的依赖关系建模能力较弱。
针对这些局限性,研究人员开始探索结合CNN与其他神经网络架构,例如循环神经网络(RNN)和Transformer模型,以提升长文本的特征提取能力。
#### 如何CNN以适应Tokenization结果?为了CNN以更好地适应tokenization的结果,研究人员可以尝试多种方法。例如,使用嵌入层将token转换为向量表示,从而保留词与词之间的语义关系。此外,调整卷积核的尺寸和层数,也能够影响模型对text feature的提取效果。
另外,可以尝试引入更复杂的网络结构,如Residual Networks或Dense Networks,以改善特征提取的能力。
#### 未来Tokenization技术的发展方向如何?在自然语言处理的不断发展中,tokenization技术也在不断演进。未来,随着深度学习模型和算法的进步,tokenization可能会更加智能化,能够自动适应不同语言与上下文,减少人为干预。
通过与新的模型相结合,例如Transformer和预训练模型(如BERT),tokenization将会在语义理解与上下文建模中更为精准,提高自然语言处理整体的效果与效率。
以上是围绕CNNs与Tokenization的详细讨论,提供了丰富的内容供进一步研究与学习。

### 内容主体大纲1. **引言** - 加密货币的崛起 - 以太坊的价值与影响2. **Tokenim项目概述** - Tokenim的背景 - 项目的主要目...

---### 内容主体大纲1. **引言** - 介绍Tokenim币的背景 - 短信链接网站的定义和普遍性2. **Tokenim币概述** - 什么是Tokenim币...
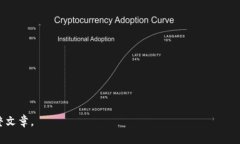
...
...